
一、从”对话匠人”到”空间玩家”
如果用一句话概括过去两年AI的发展,可以用”文字的革命”来形容。大语言模型让机器学会了写文章、作诗、写代码,甚至能够进行看似有深度的对话。但斯坦福大学教授李飞飞曾有一个精准的比喻:当前的大语言模型,本质上是在”黑暗中行走的文字匠人”——它们能精准掌握”球””重力”等词汇的语义关联,却无法真正理解当球从高处落下时的运动轨迹、碰撞后的反弹规律。
这种对物理世界的”无根性”认知,正是制约AI融入真实场景的核心瓶颈。无论是自动驾驶在复杂路况中的决策,还是机器人在生产线的精准操作,都要求AI具备对三维空间的感知与推理能力。
2026年4月,这个局面正在被改写。
二、48小时内的三次发布
4月16日,腾讯与阿里巴巴同日亮剑。
腾讯正式发布并开源混元3D世界模型2.0(HY-World 2.0),精准切入物理世界的3D数字化需求。该模型可高效理解文本、图片、视频等多模态输入,实现3D世界的自动生成、重建与模拟,支持Mesh、3DGS及点云等多格式3D资产导出,能无缝对接Unity、UE等主流游戏引擎。用户仅凭”生成一个日式RPG风格的中世纪地牢”这样的文字指令,就能获得可直接导入游戏引擎的结构完整3D空间,并支持角色自由漫游与物理碰撞。
与阿里的闭源策略不同,腾讯选择将这款3D世界模型完全开源。混元团队负责人表示,此举旨在降低游戏地图创作门槛,让普通人也能轻松搭建可玩、可用的虚拟空间,同时抢占开发者生态的先机。
阿里同日推出的Happy Oyster(快乐生蚝)则走了一条不同的路。该模型基于原生多模态架构,核心优势是能够实时构建可交互、可演绎、可探索的AI数字世界。Happy Oyster提供漫游(Wander)和导演(Direct)两大模式:漫游模式支持用户以第一人称视角在生成空间中自由移动,最长1分钟连续实时位移;导演模式则允许在视频任意节点通过多模态指令实时改写剧情、调度角色,支持连续生成3分钟以上画面。阿里将其定位为内容形态创新,瞄准影视制作、游戏开发等需要还原物理场景的核心需求。
一周后的4月23日,字节跳动由Seed团队跟进,发布新一代3D生成大模型Seed3D 2.0,API同步上线火山引擎。该模型在几何生成与纹理材质生成两项核心指标上达到当前行业领先水平(SOTA),采用由粗到精的两阶段生成策略,将整体结构与几何细节解耦优化,成功突破了锐利边缘、薄壁结构、复杂拓扑等3D生成领域的核心难点。同时借助MoE架构,大幅提升了高分辨率材质细节与边界精度。值得注意的是,Seed3D 2.0支持部件级分割与补全、铰接资产生成,以及基于文本、图像、视频的场景组合生成,生成内容可直接对接IsaacSim等物理仿真引擎,推动3D生成从单一单体模型向可交互、具身智能的场景级构建演进。
这不是巧合,而是一场集体行动。
三、三大技术路线:通往AGI的分岔路口
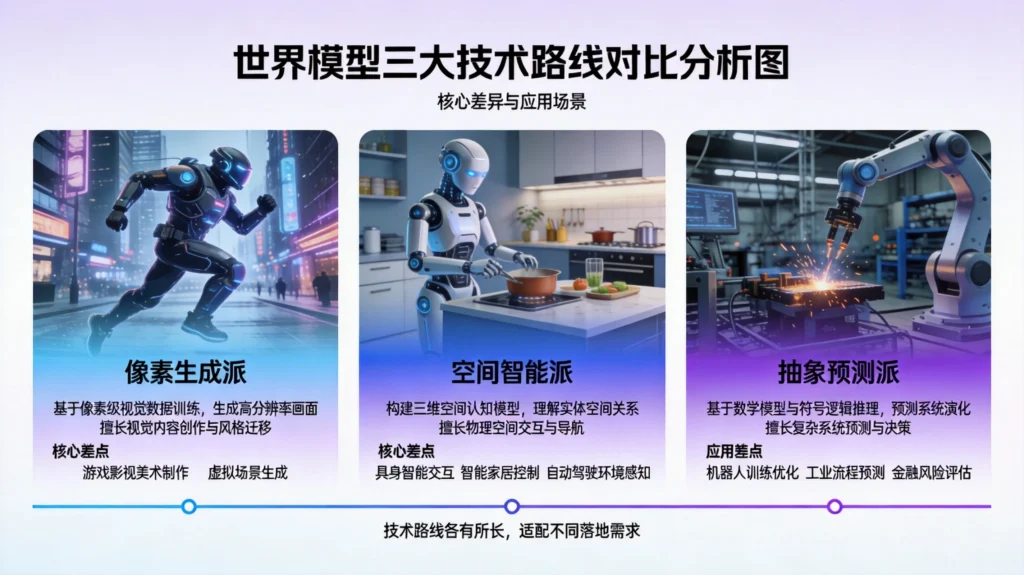
尽管统称”世界模型”,但截至2026年初,这一领域已从理论概念走向产业落地的关键分水岭,技术路线主要分为三大流派,它们在表征方式、预测目标、应用场景上存在显著差异,且暂无收敛趋势。
第一派:像素生成派(”世界即视频”)
代表玩家包括OpenAI Sora、Google Genie 3、阿里Happy Oyster、Runway GWM-1。
这一派的核心逻辑是通过视频生成技术模拟世界演化,认为”能够生成逼真视频就意味着理解了物理规律”。其技术特点是采用Diffusion Transformer或AR-Transformer架构,强调时序连贯性和画面质量,追求长时长生成(1分钟以上)。
Google Genie 3作为该流派标杆,支持实时交互、每秒24帧生成、完全交互式3D宇宙;阿里Happy Oyster则在交互时长上实现突破,漫游模式支持1分钟连续实时位移,导演模式支持3分钟以上画面。
优势在于直观、易理解,直接面向内容创作场景,商业化路径清晰。但短板同样明显:对物理规律的理解停留在表象,难以支撑机器人训练等硬核场景。批评者认为,它只是在模仿视频的表象,对于深层的物理因果(如物体碰撞后的精确受力)往往靠”猜”,容易产生逻辑漏洞。
第二派:空间智能派(”世界即3D”)
代表玩家包括斯坦福World Labs、腾讯HY-World 2.0、NVIDIA Omniverse、群核科技。
这一派的核心逻辑是真正的世界模型必须理解三维空间和物体关系,能够生成可编辑、可导出的3D资产而非仅视频。腾讯HY-World 2.0的核心差异化正是”可导出性”——生成的3D资产文件可直接用于游戏开发;群核科技则更进一步,拥有全球最大的空间数据集(15年积累),推出SpatialLM空间语言模型和SpatialGen空间生成模型。
优势在于可直接用于游戏开发、机器人仿真,工程化落地最快。劣势在于实时交互性受限,计算复杂度高,难以实现超长时序推演。
第三派:抽象预测派(”世界即因果”)
这一派跳出二维视频的思维局限,在神经网络内部直接维护一套3D表示(如高斯泼溅、点云、体素),生成持久的3D场。代表模型为World Labs的Marble、NVIDIA的Gen-3C。这一流派的核心目标不是生成”看起来像”的视频,而是真正理解物理世界的因果规律。
三种路线代表了完全不同的技术哲学。像素派追求”看起来像”,抽象派追求”理解得对”,空间派追求”用得上”。目前看来,哪一条路线能通向AGI,还没有定论。
四、应用落地:游戏影视与具身智能成核心场景
世界模型的技术突破正拓展物理世界内容生产的新空间。
在游戏行业,腾讯HY-World 2.0生成的资产可直接导入Unity、UE等引擎,传统需数十人耗时数月的3A游戏场景搭建,有望大幅降本增效。游戏开发者只需描述场景需求,AI就能生成包含物理碰撞规则的完整关卡。
在影视创作中,阿里Happy Oyster的导演模式让导演无需等待漫长渲染周期,用自然语言即可实时生成并修改分镜,缩短创意验证时间。这意味着”先拍后渲染”的传统流程可能被彻底颠覆。
具身智能与机器人成为关键延伸领域。字节Seed3D 2.0生成的内容可对接物理仿真引擎,为机器人训练提供虚拟环境。英伟达与奇瑞的合作则直接链接自动驾驶与机器人平台,呼应了2026年”十五五”规划将具身智能列为未来产业重点的政策导向。
中信证券判断,国产大模型厂商已逐步跳出参数比拼误区,聚焦智能体及代码能力升级,而具备物理世界链接能力的空间智能已成为行业布局的核心重点。
五、商业化前景与挑战
万联证券分析指出,腾讯混元世界模型2.0可将生成资产直接导入主流游戏引擎,阿里Happy Oyster适用于高保真、长时序动态场景生成,两者均有望加速游戏与影视领域的内容生产迭代。
然而,商业化路径仍待验证。世界模型在游戏、影视等场景的付费意愿、定价策略及生态建设尚不明确,且需平衡生成质量、实时性与成本控制。
技术瓶颈亦存:几何生成的泛化性、纹理贴图误差、推理效率等问题,可能影响规模化应用。字节跳动Seed团队坦言:”3D生成仍然面临几何精细度与泛化性的提升空间,纹理生成还存在遮挡与贴图误差问题。”
伦理与法律边界缺失是另一大隐患。当技术逼近物理世界,事故责任的归属问题成为最大挑战。若自动驾驶因世界模型误判导致急刹追尾,责任应由算法方还是数据提供方承担?目前,世界模型的伦理框架和法律边界远落后于技术发展速度。
六、终局预判:融合是方向,分层是路径
基于当前的技术发展和产业格局,我们可以做出一些预判:
技术路线的分层融合可能是最终解。 单一路线很难通吃。未来的超级世界模型很可能是分层架构:底层用3DGS/NeRF保证几何和物理的绝对准确(用于仿真和感知);中层用潜在空间模型(JEPA)进行高效的逻辑推理和长程规划(用于决策);顶层用像素级生成模型(Diffusion/Transformer)进行人机交互和结果展示(用于接口)。
数据飞轮决定胜负。 谁拥有最多的真实世界交互数据(尤其是机器人和自动驾驶数据),谁就能训练出最懂物理规律的世界模型。这也解释了为什么特斯拉、英伟达、谷歌等拥有硬件和数据闭环的公司处于领跑地位。
2026-2028年将是关键窗口期。 这三年,技术路线将逐步收敛,应用场景将规模化落地,产业格局将初步成型。错过了这个窗口期,可能就错过了下一个十年。
当AI开始”做梦”,当机器能够像人类一样在推演中行动,我们站在了一个新时代的门槛上。世界模型将AI从”文本匠人”提升为”物理玩家”,这场”造世界”的竞赛,才刚刚开始。
相关阅读:
- 《李飞飞重磅长文:超越语言模型,空间智能是AI的下一个十年》
- 《LLM时代终结?世界模型全面开战》
发表回复