
引言:当”默契”成为竞争新范式
2026年4月第三周,杭州和北京的两支团队,用一种近乎”隔空握手”的方式,在全球AI史上写下了独特一笔。
DeepSeek发布了V4版本,Kimi发布了K2.6。两个模型发布时间前后不过数日,总参数均超万亿,且都选择了开源。这已经是这两家公司第二次”同步”了——14个月前,它们在同一天推出了对标OpenAI o1的推理模型。
但真正让业内人士感到兴奋的,不是发布时间的巧合,而是隐藏在技术报告里的细节:这两家公司,正在用一种前所未有的方式,定义中国AI的竞争逻辑。
一、技术路线的”双轨并行”
DeepSeek V4:极致效率的工程派
DeepSeek V4的核心突破,可以用四个字概括:降本增效。
在技术上,V4开创了DSA稀疏注意力机制,结合KV Cache压缩算法,让模型在处理百万字上下文时,计算量降至上一代V3.2的27%,显存占用仅为10%。这意味着,在华为昇腾910B上,V4-Pro的推理速度能达到同等配置GPU的3.2倍。
更重要的是,V4首次将百万级上下文做成了”标配”——不需要额外付费,不需要特殊申请,所有开发者都可以直接调用。
在生态布局上,DeepSeek选择了与华为昇腾深度绑定。V4是全球首个完全脱离英伟达CUDA生态、运行于华为CANN框架的万亿参数大模型。字节跳动、阿里巴巴等大厂已预订数十万片昇腾950芯片,形成了”模型验证芯片→巨头采购→量产摊薄成本→模型更便宜”的正向飞轮。
Kimi K2.6:生产力导向的场景派
与DeepSeek的”工程派”路线不同,Kimi K2.6走的是”场景派”路线——它的核心目标,是让大模型真正成为可承接真实工作的生产力工具。
K2.6的核心升级,围绕三个关键词:长程编码、Agent集群、工具调用。
在代码能力上,K2.6以58.6分登顶全球权威代码评测榜单SWE-Bench Pro,超越GPT-5.4(57.7分)和Claude Opus 4.6(53.4分)。这是国产开源模型首次在这一领域登顶。
在Agent能力上,K2.6支持最高300个子Agent并行,可完成4000个协作步骤。在内部测试中,K2.6实现了连续编码13小时不间断,多Agent协同处理复杂工程任务的能力显著提升。
在架构创新上,Kimi推出了Kimi Linear混合注意力架构,把线性注意力和全注意力以3:1的比例混合,在长上下文推理中,解码速度提升最高达6倍,KV缓存减少75%。
二、技术架构的”隔空接力”
如果只是路线的差异,还不足以让这次发布引发如此大的关注。真正的亮点,藏在技术报告的引用列表里。
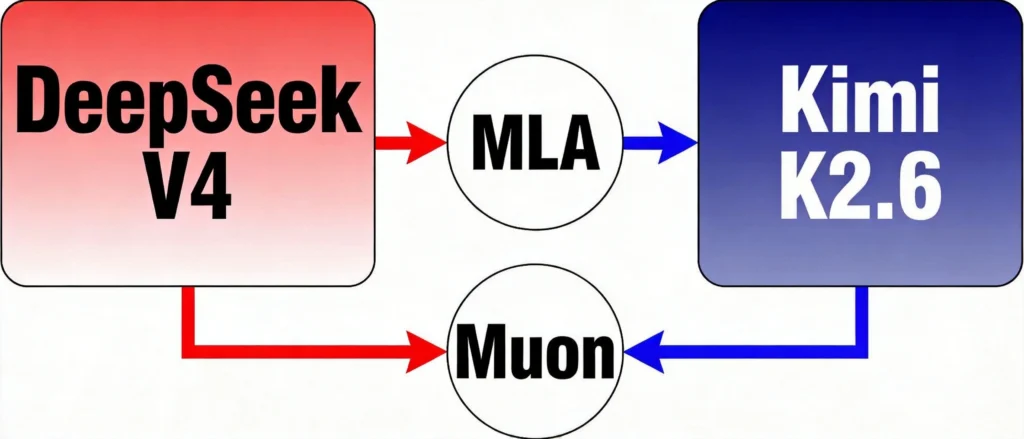
MLA:从DeepSeek到Kimi的技术传递
DeepSeek V3提出的MLA(多头潜在注意力)技术,是它最核心的架构创新之一。通过压缩KV缓存,MLA能大幅降低大模型的推理成本——要知道,推理成本是大模型落地的最大门槛之一。
而Kimi在K2系列模型中,选择沿用了MLA架构。靠着这项技术,Kimi成功压缩了KV缓存体积,为Agent能力的落地扫清了障碍。
换句话说:DeepSeek的MLA,帮Kimi降低了推理成本。
Muon:从Kimi到DeepSeek的优化器传递
反过来,Kimi率先大规模验证的Muon优化器,解决了万亿参数大模型训练不稳定、效率低的行业难题。实现了”同等训练量下效率翻倍”,相当于把50万亿token用出了100万亿的效果。
而DeepSeek V4的技术报告里,直接把Muon优化器写进了训练方案。
Kimi的Muon,帮DeepSeek降低了训练成本。
你用我的架构,我用你的优化器。没有纠纷,不用授权。这就是中国开源AI独有的正向循环模式。
与硅谷的对比:闭源的内斗 vs 开源的接力
说到这里,就不得不提OpenAI和Anthropic的”斗争史”了。
Anthropic的核心团队大多来自OpenAI,因为理念不合出走后,直接对标OpenAI做闭源模型。双方在技术、人才、资本上展开全方位竞争。
从2023年到2026年,Anthropic的年化收入几乎每年都在以10倍的速度增长,步步紧逼OpenAI。2026年2月,Anthropic完成300亿美元融资,估值达3800亿美元。据传,OpenAI近期甚至在内部备忘录中,明确将对方锁定为”首要威胁”。
闭源模型的盈利模式,决定了它们必须是”绝对竞争”的关系——蛋糕就这么大,你多吃一口,我就少吃一口。
而中国AI面临的宏观环境截然不同。在算力受限、高端芯片被海外”卡脖子”的底色下,中国企业若继续内耗,无异于自绝前路。
因此,DeepSeek和Kimi果断选择了拥抱开源——把蛋糕做大、合力突围。
三、两条路线的”殊途同归”
DeepSeek:工程适配路线
DeepSeek走的是”工程适配”路线。V4首发适配华为昇腾芯片,工程团队硬生生把整个技术栈从CUDA迁移到华为CANN框架。
从算子库、通信原语到内存管理,几乎每一层都重新实现。团队还完成了寒武纪芯片的Day 0适配,代码全部开源,用实际行动证明:国产芯片也能跑万亿参数的旗舰大模型。
连英伟达CEO黄仁勋都曾坦言,”如果DeepSeek先在华为平台发布,对我们来说非常可怕”。如今这句话已然成真。
Kimi:架构创新路线
Kimi走的是”架构创新”路线。
为了适配国产芯片,它掏出了两大”杀手锏”:
第一,Kimi Linear混合注意力架构。 把线性注意力和全注意力以3:1的比例混合,让RDMA高速网络从”必选项”变成”可选项”。
第二,PrFaaS技术。 把推理的预填充和解码阶段彻底解耦,调度到不同的国产异构硬件上。相比传统同构PD部署,实测吞吐量提升54%,P90延迟降低64%,彻底打破了”大模型推理必须绑定高端GPU”的魔咒。
一个从工程层面验证国产芯片的承载能力,一个从架构层面优化国产芯片的运行效率。两家公司用不同的方式,共同推动”中国芯片+中国模型”的生态落地。
四、全球影响力:从”跟随”到”共振”
2026年春季,一系列事件显示,中国AI的影响已开始溢出本土,在全球舞台引发回响。
硅谷的”转身”时刻
3月的英伟达GTC大会上,黄仁勋展示新一代硬件性能时,选择的基准模型正是DeepSeek和Kimi。对于长期以欧美模型为性能标杆的行业而言,这一选择信号鲜明。
同月,硅谷明星编程工具Cursor发布其”自研”旗舰模型,但开发者从日志中发现其底层调用了Kimi的API。连马斯克也下场确认了这一事实。
无独有偶,由日本官方资助、日本乐天集团发布的”自研”大模型,其关键参数被开发者指出与DeepSeek V3高度相似。
这些”技术撞车”事件,并非单纯的模仿,而更像是一种基于实用主义的”用脚投票”——全球开发者在选择当前最具性价比或最适用的技术方案。
市场数据的印证
监测平台OpenRouter显示,一季度全球API调用量中,中国开源大模型的周词元(Token)调用量占比已经超过60%,Kimi和DeepSeek占据前列。
QuestMobile数据显示,截至2026年3月,豆包月活3.4亿、千问1.7亿、DeepSeek 1.3亿。国产AI在应用规模和生态活跃度上已实现历史性反超。
这标志着,技术影响力的流动方向正在发生静默而深刻的转变:从过去数十年硅谷向全球的单向辐射,逐渐转变为多极节点间的双向甚至多向流动。
五、从”追赶”到”并跑”的深层信号
14个月前,产业的核心焦虑是”我们能否做出世界级的基础模型”,这是一个关于”从0到1″的生存之问。
14个月后,问题已演变为”我们能否在受限的生态中,让技术能力的持续跃迁成为常态”,这是一个关于”从1到N”的发展之问。
问题的演变,本身便是产业从追赶迈入并跑甚至局部领跑阶段的注脚。
不再依赖”英雄叙事”
DeepSeek与Kimi的”双星共振”,恰是中国AI在当前历史节点的生动缩影。它并非精心策划的协同,而是在共同的国家战略牵引、相似的资源约束条件与开放的工程师文化催化下,自然生长出的一种生态默契。
它们的故事表明,中国AI的突破,可能不再依赖于某个天才的”灵光一现”或单一企业的”英雄叙事”,而是依靠一个能够实现技术接力、共担创新风险、共享基础进步的坚韧生态。
国产算力的”破局”
最大的风雨无疑来自算力约束。在美国持续收紧高端AI芯片出口的背景下,中国AI公司不得不”戴着镣铐跳舞”。
然而,压力催生了惊人的效率革命。DeepSeek V4实现了标志性突破:在同等性能下,其推理算力需求骤降至上一代的27%。更为关键的是,团队明确宣布V4基于华为昇腾芯片训练。
这意味着,突破算力瓶颈的答案,不只有”获得先进芯片”这一条路。通过极致的算法优化、架构创新与软硬协同,在有限硬件上挖掘极限性能,正成为中国AI的一项核心能力。
这条被”逼出来”的高效之路,或许将塑造出区别于美国”暴力计算”路线的另一技术范式。
结语:共振,才刚刚开始
当DeepSeek在V4公告中写下”从现在开始,1M上下文将是标配”,当Kimi在K2.6的测试中让智能体自主连续运行了整整五天,中国AI已经悄然越过了以参数论英雄的蛮荒期。
这不仅意味着中国企业在复杂的全球AI棋局中,找到了绕过算力封锁的解题钥匙,更深远的意义在于,随着国产算力的大规模放量以及中国开源大模型在全球占比份额的迅速攀升,一种崭新的世界AI多极化格局已见雏形。
当一个行业的壁垒从封锁变成效率,从闭源的神秘变成开源的普惠,真正的风暴才刚刚开始。
当硅谷放眼东方时,它所见的不仅是中国公司的崛起,更可能是一种不同创新范式的生长。这场始于东方、回荡于全球的”共振”,或许才刚刚奏响序曲。
相关阅读:
- [国产AI芯片市占率突破41%:华为昇腾领衔,从”替代”走向”超越”]
- [AI智能体从”玩具”到”数字员工”:企业级落地全解析]
发表回复