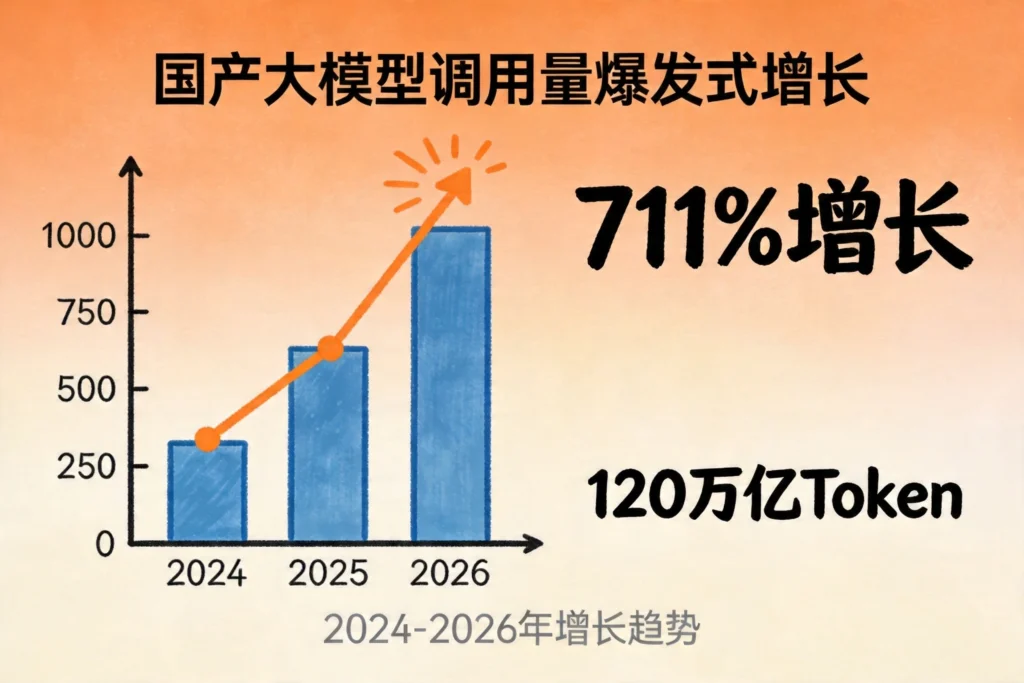
一、里程碑时刻:国产芯片市占率首破四成
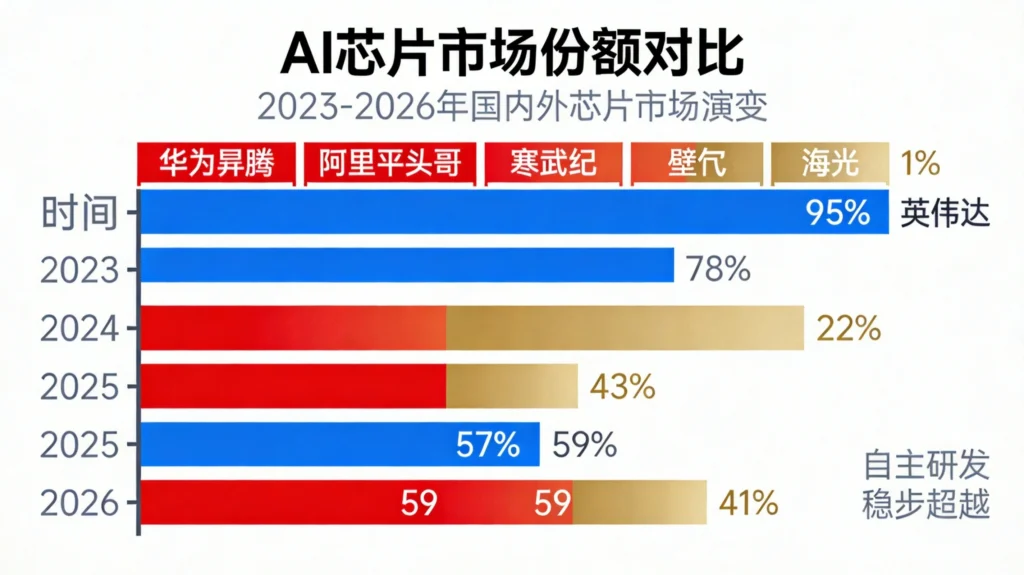
从95%到41%:三年格局逆转
2026年4月,一组来自IDC全球半导体行业报告的数据震撼业界:三年前(2023年),中国AI芯片市场英伟达一家独大,份额高达95%,近乎完全垄断;2025年底,国产芯片市占率首次突破41%;2026年一季度,国产份额稳定在41%,英伟达在华份额进一步下滑至55%,美国机构预测年底将跌破8%。
这是一个历史性的转折点。三年前,当美国对华高端GPU限制持续升级、英伟达A100/H100等旗舰产品在华供应基本切断时,业界曾担忧中国AI产业将因“缺芯”而陷入困境。如今,事实给出了截然不同的答案。
字节、阿里、百度集体切换国产
更令市场振奋的是,字节跳动、阿里巴巴、快手、百度等国内头部互联网大厂已全部切换国产芯片,英伟达高端芯片H200在华出现“零采购、零订单”的尴尬局面。
这一转变背后,是国产芯片在性能、价格、交付周期上的全面竞争力。以往“性能差、生态弱”的标签正在被撕掉,取而代之的是“性价比高、本地化服务强、供应链安全有保障”的新形象。
二、硬核产品矩阵:五路大军突围
华为昇腾950PR:国产性能王
2026年3月正式量产的华为昇腾950PR,是目前国产性能最强的AI芯片,专门对标英伟达高端旗舰H200。
算力硬实力:FP4精度下,单卡算力达英伟达H20的2.87倍;FP8推理场景下,性能是英伟达特供版H20的2倍。这意味着在同等条件下,昇腾950PR能以更低的硬件数量完成更高的吞吐量。
显存规格:搭载112GB自研HiBL 1.0 HBM高速显存,处理海量数据不卡顿。虽然是自研技术路线,但在容量上已与国际主流产品看齐。
价格优势:低配版单价仅5万元,高配版7万元,只有英伟达H200的一半左右。对于需要大规模部署的企业而言,这意味着成本的大幅削减。
量产交付:2026年全年预计交付75万片,交货周期2-4个月,比英伟达的数月等待更具时效性。
落地应用:已在国内多个大型数据中心落地,支撑文心一言、通义千问、GLM-Image等国产大模型训练。更具标志性意义的是,首个全程用国产芯片训练的全球顶级多模态模型已经诞生。
阿里平头哥真武810E:出货量第一
2026年1月正式官宣的阿里平头哥真武810E,秘密研发5年,一出道即巅峰。官宣1个月就拿下国产GPU出货量第一,累计出货超百万片,服务400+客户。
真武810E的核心优势在于生态闭环——阿里“大模型+云+芯片”全栈自研,通义千问、阿里云、真武芯片深度适配。这是全球第二家、国内首家实现全栈自研的科技公司,意味着从底层芯片到上层应用,全链条自主可控。
寒武纪思元590:推理场景性能王
寒武纪思元590主打大模型推理,性能已超越英伟达H20,已在金融、互联网场景规模化应用。作为国内AI芯片龙头的代表性产品,思元590的成功证明了国产芯片不仅能在性能上追赶国际巨头,还能在特定场景形成领先优势。
壁仞BR100:科学计算专用
壁仞BR100专注于科学计算、自动驾驶仿真专用场景,性能接近英伟达A100,稳定量产交付。虽然通用性不及头部产品,但在垂直领域形成了自己的竞争力。
海光信息DCU:兼容生态最广
海光信息采取“CPU+DCU”双线布局,DCU产品兼容性最强,与DeepSeek、Qwen3、混元等365款大模型完成联合精调,覆盖全球99%非闭源模型。这种广泛的适配性,使海光成为国产替代中“最省心”的选择。
三、全产业链突围:从设计到制造
芯片设计:五大核心阵营成型
目前,国产AI芯片已形成“华为昇腾、阿里平头哥、寒武纪、壁仞、海光”五大核心阵营,覆盖训练、推理、通用计算全场景。设计能力达到国际一流水平不再是口号,而是实打实的产品支撑。
芯片制造:中芯国际7nm稳定量产
最关键的制造环节,国内已绕开美国限制的EUV光刻机,用DUV多重曝光技术实现7nm N+2工艺稳定量产。良率高达99.7%,性能接近国际5nm水平。北京、上海两大工厂月产能超5万片,足够支撑华为、阿里等高端芯片制造。
设备材料:28nm光刻机交付
上海微电子28nm浸没式DUV光刻机已实现量产,国产化率85%,售价仅为进口的60%。硅片、光刻胶、特种气体等关键材料国产化率达75%,不再依赖海外进口。
从设计到制造,从设备到材料,国产AI芯片产业链每一环都实现了自主突破,彻底摆脱了被“卡脖子”的风险。
四、DeepSeek-V4:国产算力闭环的关键拼图
彻底摆脱CUDA生态
2026年4月24日,DeepSeek-V4预览版正式上线并开源,首次彻底摆脱英伟达CUDA生态,全面适配华为昇腾芯片。这一突破意味着什么?
长期以来,英伟达的CUDA编程工具自2007年起仅限英伟达平台使用,绑定了全球开发者生态。开发者习惯使用CUDA后,切换到其他平台成本极高。DeepSeek-V4通过自主开发的底层框架,完全绕开CUDA,直接适配华为CANN框架,为国产芯片打通了软件生态的“最后一公里”。
推理速度提升35倍
更重要的是,DeepSeek-V4在华为昇腾平台上的推理速度提升达35倍。这一数字的意义在于,它证明了国产芯片+国产框架的组合,不仅在性能上可以追赶国际巨头,在效率上同样可以实现超越。
DeepSeek-V4与华为昇腾的适配,标志着“国产大模型+国产全栈算力”闭环正式落地。中国AI产业第一次拥有了从底层芯片到顶层应用的完整自主链条。
五、从“替代”到“超越”:国产芯片的差异化路径
推理优先策略
国产芯片的突围并非盲目追赶,而是在战略层面做出了聪明选择——推理优先。相比训练,推理是大模型应用的主要场景,且推理芯片的技术门槛相对较低,更适合后发者切入。
华为昇腾950PR在推理领域的性能已全面超越英伟达H20,在电商推荐、工业质检等场景实现商用,时延低于10ms,转化率提升15%。这种场景化的成功,正在为国产芯片积累口碑和信任。
集群技术:以量补质
在高端训练芯片领域,国产与国际仍有差距。但通过超节点架构,国产芯片实现了系统级的突破。例如,通过384颗昇腾芯片组合,整体算力可反超英伟达GB200集群1.7倍。这是典型的“以量补质”策略——单卡性能不足,用集群规模来弥补。
场景化定制
未来,国产芯片将进一步走向场景化定制。云端训练聚焦超大算力、高带宽,采用Chiplet+HBM架构;云端推理聚焦高能效、低成本,ASIC与优化型GPU主导;边缘终端聚焦低功耗、高实时性,NPU与轻量级ASIC成为主流。
六、未来展望:2030年国产主导
短期预测(2026-2027)
国产芯片在推理、边缘端将实现全面替代,训练领域逐步缩小差距。华为昇腾市占率预计升至50%,英伟达进一步萎缩至8%以下。
中期目标(2028-2030)
国产AI算力芯片国内市场占有率将达到40%,在推理端实现全面主导,训练端进入全球第一梯队。通过Chiplet、光芯片等新技术重构赛道,结合AI应用场景优势,实现全球生态话语权。
长期愿景
从“能用”到“好用”再到“主导”,国产AI芯片正在走出一条与美国截然不同的道路。美国走的是“更高算力+更强芯片”的上限突破路线,中国走的是“普惠算力+广泛应用”的深度渗透路线。两条路线各有优劣,最终谁将赢得产业主导权,还需要时间来验证。
但至少现在,中国已经证明:封锁越紧,国产越强。这是中国科技的韧性,也是中国芯的故事。