一、万亿豪言:算力需求的新纪元
2026年3月的圣何塞,英伟达GTC开发者大会再次成为全球科技行业的焦点。英伟达创始人黄仁勋在主题演讲中抛出了一组令华尔街震惊的数字:预计2027年,基于Blackwell及下一代Vera Rubin平台的采购订单将达到至少1万亿美元。这个数字在半年前同类预测中还是5000亿美元——短短六个月,需求翻了一倍。
“这不是狂妄,而是保守。”黄仁勋补充道,“事实上,我们甚至会供不应求。我确定,实际的计算需求会比这高得多。”
支撑这一激进预测的,是AI产业“推理拐点”的全面到来。从ChatGPT开启生成式AI时代,到o1模型带来推理能力突破,再到Claude Code引爆Agentic AI热潮,过去两年间,单次AI工作的计算需求提升了约1万倍,使用量提升了约100倍,计算总需求的增幅接近100万倍。
英伟达重返5万亿美元市值关口,以一己之力超越英法两国股市总和,再次稳坐全球上市公司市值榜首。这不仅是市场对英伟达基本面的确认,更是对AI算力需求爆发式增长的一致预期。
二、算力价格暴涨:供需失衡的最直接信号
算力租赁价格的飙升,最直观地反映了高端AI芯片的供需缺口。
SemiAnalysis发布的数据显示,单块英伟达H100的一年期租赁价格从2025年10月的低点1.7美元/小时飙升至2026年3月的2.35美元/小时,涨幅近40%。而新一代Blackwell芯片的涨势更为惊人,单小时租金在短短两个月内从2.75美元涨至4.08美元,涨幅达48%。
高端算力供不应求的格局,已从供应链上游蔓延至终端计价环节。这意味着,英伟达不仅掌握着芯片的定价权,更掌握着整个AI产业的成本定价权。
2026财年第四季度,英伟达营收681亿美元,同比增长73%;全年营收首次突破2000亿美元大关,达2159亿美元。数据中心业务单季营收623亿美元,同比增长75%,占公司总营收比重超过90%。75.2%的非GAAP毛利率,在全球硬件公司中堪称独一档的存在。
三、Token工厂经济学:重构数据中心的底层逻辑
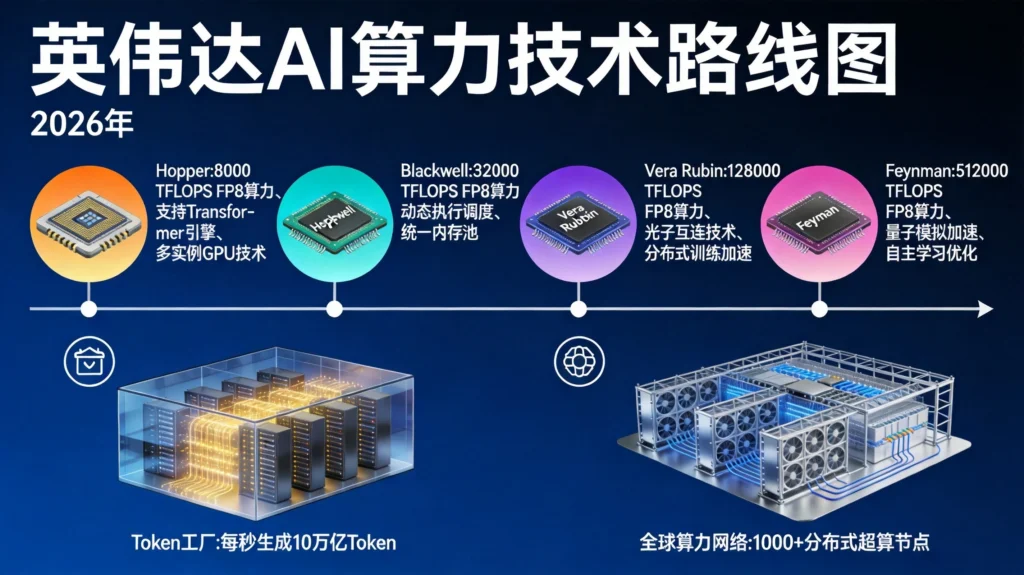
GTC演讲中,黄仁勋抛出了一个彻底重构数据中心概念的命题:“未来的数据中心不再是存储文件的仓库,而是生产Token的工厂。”
Token是AI大模型理解和生成语言的最小语义单元。在黄仁勋的叙述框架中,Token就是AI时代的“数字石油”。他的论证逻辑简单而有力:每一座数据中心都受到严格的电力约束,一座1GW的工厂永远不会变成2GW——这是物理世界的铁律。因此,在固定功率下,决定生产成本和盈利能力的唯一变量,就是每瓦电的Token吞吐量。
从这个逻辑出发,黄仁勋做出了一个近乎傲慢的断言:“英伟达的Token成本在世界范围内是’不可触碰’的。即便竞争对手的架构是免费的,它也不够便宜。”
这不是营销话术,而是基于软硬件垂直整合的计算经济学。研究机构SemiAnalysis的评测显示,从上一代Hopper H200到Grace Blackwell NVLink 72架构,英伟达的每瓦特性能提升了约35倍。建立一个1GW数据中心仅15年摊销成本就高达400亿美元,低效的芯片在其中每多运行一天,都在烧钱。
这套商业思维将AI服务划分为从免费层到超高速层的五个商业层级,超高速层每百万Token可达150美元。黄仁勋还描绘了一个令人难忘的职场图景:未来每一位工程师都需要一个年度Token预算,公司会在基础年薪之外额外配给大约一半金额的Token额度。“你的offer里带多少Token?”——这句话正在成为硅谷最新的招聘筹码。
四、Vera Rubin:七芯片组合拳构建系统级壁垒
黄仁勋的万亿豪言,需要足够强大的产品来兑现。在GTC 2026上,英伟达给出的答案是堪称公司史上最复杂的AI计算系统——Vera Rubin。
Vera Rubin不是一个传统意义上的GPU产品,而是一个由七款芯片和五种机架系统组成的完整AI超级计算机平台。它集成了Vera CPU、Rubin GPU、NVLink 6交换机、ConnectX-9 SuperNIC、BlueField-4 DPU、Spectrum-6以太网交换机,以及从收购公司Groq整合而来的Groq 3 LPU。
这套组合拳清晰地宣示了英伟达从单一GPU供应商向全栈AI基础设施平台的彻底蜕变。
在技术指标上,Vera Rubin实现了代际级别的跃迁。Rubin GPU采用台积电3nm先进制程,集成了3360亿颗晶体管,较前代Blackwell大幅提升六成以上。其FP4推理算力达到50 PFLOPS,是Blackwell的5倍,每瓦特性能提升达4倍。
五、光互联革命:硅光商用元年开启
AI大模型的真正瓶颈往往不在GPU本身,而在于数万颗芯片间的数据传输。在英伟达现有的NVL72系统中,无源全铜缆网络导致信号在传输约2米至2.5米后就会衰减到无法使用,迫使计算和交换机托架必须紧密排列,且满负荷运行时功耗高达132至220千瓦。
这种“通信墙”问题使得大量GPU时间耗费在等待数据上,算力利用率严重不足。光互联凭借其高带宽、低损耗和低能耗的特性成为破局关键。英伟达在GTC大会上发布的Feynman芯片,通过光通信芯片间互联将传输能耗降低70%以上。
IEEE高级会员、北京邮电大学教授顾仁涛明确指出,2026年被广泛视为CPO(共封装光学)技术的量产元年。集邦咨询预测,全球AI专用光收发模块市场规模将从2025年的165亿美元增至2026年的260亿美元,年增幅超过57%。
中国企业在这一领域同样表现亮眼。中际旭创作为全球硅光模块龙头,在800G硅光模块市占率约50%,并是英伟达GB200平台1.6T硅光模块的独家供应商。曦智科技已于2026年4月通过港交所聆讯,冲刺成为“全球AI硅光芯片第一股”。
六、AI智能体时代的基础设施支撑
GTC 2026的另一个核心主题是AI智能体(Agentic AI)的崛起。黄仁勋宣布推出对标OpenAI的AI智能体平台,支持工业制造、办公文档、智能家居等多场景的自主任务执行,能够自主学习用户习惯,优化交互体验。
大会还重点介绍了OpenClaw——这个由开发者Peter Steinberger发起的开源项目,GitHub星标已超28万,成为平台上增长速度最快的项目之一。黄仁勋评价道:“OpenClaw开源了智能体计算机的操作系统。现在,OpenClaw让我们能够创建个人智能体。”
“当今世界上的每一家公司都必须制定OpenClaw策略。”黄仁勋表示。
为了确保这项技术可以在企业内部安全部署,英伟达介绍了NVIDIA OpenShell项目——一个在NVIDIA基础设施上安全运行OpenClaw的框架。同时宣布推出NVIDIA NeMoClaw,使开发者能够更轻松地在NVIDIA驱动的基础设施上安全地构建、部署和加速AI智能体。
七、展望:未来三年的技术路线图
从Vera Rubin之后,英伟达的下一代重要架构是Feynman。该架构将包含一个新的CPU:NVIDIA Rosa——名称来自Rosalind Franklin,其X射线晶体学揭示了DNA的结构。Rosa将配合新一代LPU LP40、BlueField-5和CX10,通过Kyber实现铜缆和光电一体封装的纵向扩展,以及Spectrum级光学横向扩展。
Feynman系列处理器推进了AI工厂的各个支柱发展,包括计算、内存、存储、网络和安全。为了帮助加速新AI能力的横向扩展,英伟达宣布推出NVIDIA Vera Rubin DSX AI Factory参考设计和NVIDIA Omniverse DSX Blueprint,让企业能够在软件中模拟仿真AI工厂,然后再在物理世界中建造它们。
最后,黄仁勋宣布英伟达将布局太空。新的Vera Rubin架构以发现暗物质的天文学家维拉·鲁宾命名,而NVIDIA Space-1 Vera Rubin等未来系统旨在将AI数据中心送入轨道,将加速计算从地球扩展到太空。
八、结语
GTC 2026清晰地展示了AI算力竞争的新逻辑:从单芯片性能的比拼,转向系统级效率的较量;从单纯的训练算力,扩展到推理与执行的全面支撑;从孤立的GPU供应商,进化为全栈AI基础设施平台。
“Token工厂”时代的到来,意味着算力将从稀缺资源变成基础设施,而在这个过程中,谁能提供更低成本、更高效率的Token生产能力,谁就掌握了AI时代的话语权。英伟达显然正在用技术、产品和生态,构建这道越来越高的壁垒。