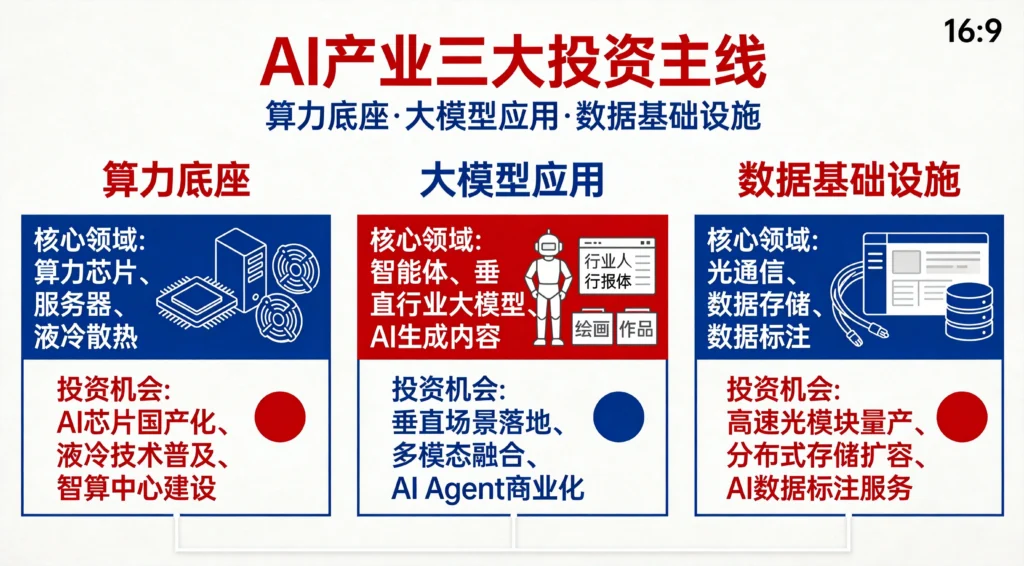
一、量产之后:机器人该何去何从
2026年3月,智元机器人第一万台通用具身机器人正式下线。消息一出,业界振奋。但紧接着,一个更现实的问题浮出水面:万台量产之后,这些机器人该往哪里去?
这个问题的答案,或许比量产本身更关键。
回望2025年,具身智能行业完成了重要一跃——量产门槛被正式跨越。智元机器人在年初刚实现千台出货,到年末已攀升至超5100台;优必选全年交付全尺寸人形机器人1079台,人形机器人业务收入同比增长超过22倍。
但热闹背后也有隐忧。一位长期关注机器人行业的投资人曾私下感叹:”现在的问题是,机器人厂商能造出机器人了,但市场还不知道该怎么用。”
进入2026年,行业主旋律正在迎来新一轮转变。
智元机器人联创彭志辉年初曾表示,具身智能行业已从实验室炫技、Demo展示,进入工程化、场景化竞争的下半场。如果说2025年解决了能不能做出来的问题,那么2026年的核心命题就是——怎么让机器人做成事。
具体来说,就是让Demo走进真实工厂,让量产转化为规模化部署,让概念验证转化为可复用的商业价值。
与此同时,一个清晰的共识正在行业形成:2026年,具身智能正式进入单场景落地元年。
而落地实践中的场景主线,将是工业场景。
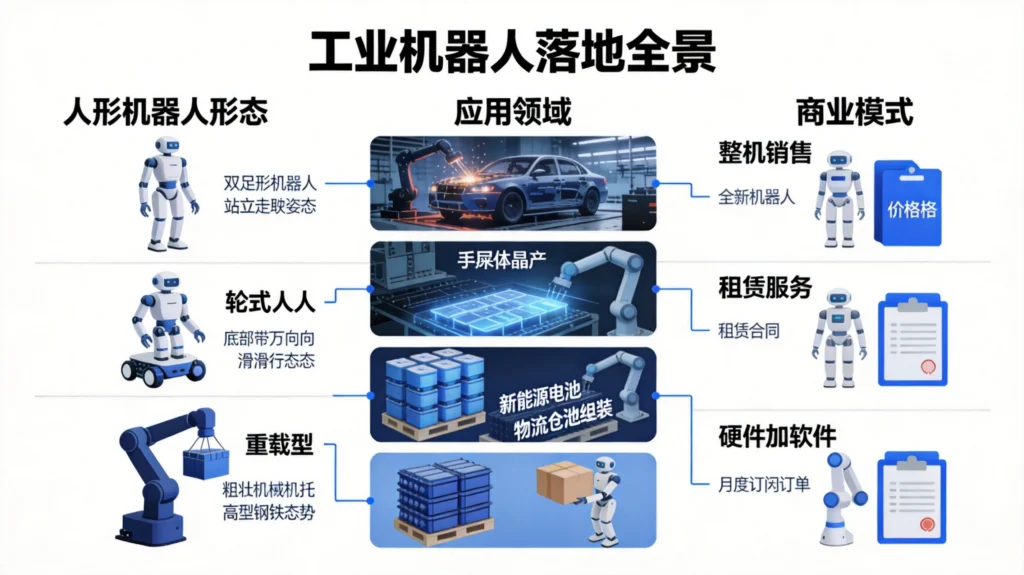
二、为什么工业场景是首选战场
在高端制造领域,半导体、新能源、3C电子等行业对柔性生产、极致精度、持续效率和零容错安全的要求已经到了临界点。
半导体制造需要在ISO CLASS 3级洁净度环境下完成晶圆搬运与封装测试,新能源电池生产需要毫米级精度的电池接插件插接,3C电子制造则要求应对频繁换线的柔性作业能力。
传统自动化设备依赖预设程序和固定轨迹,无法适应小批量多品种的柔性生产需求,产线上大量非标准化操作仍然依赖人力。
与此同时,制造业劳动力结构性短缺日益突出,高危岗位替代和产能波动适配也逐渐成为当下工业刚需。
换句话说,工业场景迫切需要一套能”看懂、想明白、动手做”的自主智能解决方案。
从更深层来看,制造业数字化转型已经经历了十余年,信息流的打通已接近天花板,但物理世界的物质流依然是孤立、僵化的存在——设备、物料、人员之间缺乏实时的智能交互与协同。
具身智能作为能自主感知、决策、行动的物理智能体,恰恰是打通数字世界与物理世界的关键桥梁。
当具身智能技术进入工厂,它带来的改变是全流程的。机器人不再依赖预设程序,而是通过自主感知、实时决策和精准执行,形成闭环能力,能在复杂工位间灵活切换任务。在半导体晶圆搬运、新能源电池组装这类高精密场景下,它能实现毫米级操作、低震动、高稳定运行,直接满足产线严苛标准。
从实效成果来看,效率提升、不良率下降、7×24小时连续运行的叠加效应,让具身智能成为制造业降本增效的全新变量。
工业场景之所以能率先落地,背后有三条清晰的底层逻辑:
首先是场景的高度结构化。 工业车间、物流仓储等封闭或半封闭环境,规则清晰、障碍物固定、任务流程标准化,相较于开放环境,降低了模型的训练难度与环境适配成本,让技术落地的成功率与稳定性更有保障。
其次是成熟的商业闭环。 工业企业具备清晰的成本核算逻辑与强劲的付费意愿,政策层面对智能制造、新质生产力的扶持力度持续加大。具身智能的投入能通过效率提升、人力节约、品质优化等维度形成明确的投资回报,回报周期通常控制在3-5年,符合制造业的投资预期。
最后是风险的可控性。 封闭的工业环境能有效减少外部突发干扰,便于企业进行小范围试点验证、逐步规模化推广,同时便于技术厂商进行远程运维与模型迭代。
这种稳健的落地路径,既降低了客户的试错成本,也为技术的持续优化提供了安全的试验田。
三、机器人已经进入哪些工厂
当工业场景的价值被广泛认可,一场关于路径选择与技术形态的竞赛也随之展开。
一些企业选择人形路线,凭借灵活双足和灵巧操作能力,直接切入汽车等复杂制造产线。
优必选的Walker S系列已批量进入富士康、比亚迪、极氪等头部制造企业的生产线,承担搬运、上下料、分拣等核心工序。目前单台机器人作业成功率已达99%,智能搬运环节的效率从2025年初相当于人工的30%提升至当前60%。
Figure AI的F.02机器人则在宝马工厂连续运行11个月,完成10小时轮班,累计运行1250多小时,装载9万多个零件,助力生产超过3万辆X3车型。
开普勒机器人的K2″大黄蜂”则在上汽通用物流工厂、兆丰股份零部件车间、纯米科技和露笑科技工厂落地,作业成功率达98%,还完成了全球首例人机协作高空焊接。
另一类企业专注重载能力,解决工业核心环节的大件搬运难题。
银河通用的Galbot S1双臂最大持续负载达到50公斤,已在宁德时代产线实现零遥操、全自主作业,承担先进制造中的重载关键任务。
鹿明机器人的MOS轮臂式具身智能机器人同样刷新50公斤双臂负载纪录,目前已在三菱电机启动实证测试,并落地中远海运等头部场景。
还有企业以轮式形态切入特定高价值产线。
千寻智能的人形机器人”小墨”已在宁德时代PACK生产线实现全球首条具身智能规模化落地,单日工作量较人工提升3倍。
智平方的AlphaBot系列则在汽车制造、生物科技和半导体显示面板领域多点开花。与惠科股份达成签下的5亿元大单,覆盖仓储物流、上下料、装配到质检的全链条场景。
四、商业模式:租赁还是销售
机器人进工厂不难,难的是找到可持续的商业模式。
目前行业内主要有三种商业模式探索:
第一种是整机销售。 这是最传统的模式,机器人厂商将整机出售给终端客户,一次性回款。优势是收入确认简单,劣势是客户前期投入大,决策周期长,且售后服务边界容易模糊。
第二种是租赁+服务分成。 部分厂商开始探索租赁模式,将机器人以月租形式提供给工厂,同时收取一定的服务费用。这种模式降低了客户的使用门槛,也给厂商带来了持续的现金流。浙江某租赁商透露,一台人形机器人每天可接三单,热门舞蹈开发后租赁价格还能上涨,一年可收回超百万元成本。
第三种是”硬件+软件订阅”三重变现。 广州酷库智能的AI咖啡师模式值得关注:单机约10个月回本,日均营收超5000元。公司转向”硬件+流水分成+软件订阅”三重变现,硬件本身可能微利甚至平价出货,真正的利润来自持续的软件服务费和数据运营价值。
TrendForce集邦咨询预测,2026年中国人形机器人市场产量将同比激增94%,下半年全球产业进入商业化关键期。但商业化成熟与否,不能只看出货量,更要看这些机器人能否在真实场景中创造持续价值。
五、三重门槛:技术、成本与生态
尽管工业场景的价值被广泛认可,人形机器人的商业化落地仍面临三重门槛。
第一道门槛是技术。
当前人形机器人在感知泛化能力上仍有明显短板。世界模型仍处于早期阶段,机器人在跨场景迁移、应对突发情况时的能力较弱。一位在汽车工厂部署机器人的工程师坦言:”工厂里的零件摆放不可能每次都一样,机器人需要能够适应各种’意外’,但目前的泛化能力还不够。”
灵巧手的负载、精度、成本难以平衡。人形机器人需要完成拧螺丝、插拔线束等精细操作,对灵巧手的要求极高。目前12自由度灵巧手已实现批量量产,指尖力反馈精度达到0.1N,但单套成本仍在十万级别,距离消费级普及还有距离。
续航同样是痛点。目前最长续航约4小时,而工业场景往往需要8小时以上的连续作业能力。
第二道门槛是成本。
消费端,78%用户对家庭机器人的心理价位在千元内,而能自主行动的高端机型售价仍在万元级以上。工业端,人形机器人单价在15-200万元,投资回收期超过3年,对比专用机械臂(均价5-10万元)性价比劣势明显。
第三道门槛是生态。
人形机器人的普及需要整个产业链的协同,包括核心零部件国产化、数据训练标准建立、售后服务网络搭建等。目前核心零部件国产化率已超过85%,但AI推理芯片国产化率仍不足10%,80%以上依赖英伟达。
六、未来路径:分层推进,场景深耕
行业共识是,人形机器人的普及将是一个渐进过程。
政策层面正在构建”标准-场景-成本-生态”四维支撑体系。工信部于2025年发布首个人形机器人国家标准,覆盖零部件安全、伦理规范和应用场景。地方政策如北京亦庄出台”具身智能十条”,打造全栈式开发者社区,加速产业链集聚。
技术演进聚焦自主导航与智能化。2026年北京人形机器人半程马拉松赛事中,自主导航参赛占比从去年不足10%跃升至40%,赛事规则通过加权系数倒逼企业攻克自主技术。银河通用研发的全球首款全自主网球人形机器人,正手击球成功率高达90.9%,展示了在非结构化场景下的实时决策能力。
商业化将分层推进: 工业场景继续深耕汽车、3C等标准化领域;家庭场景从养老陪护、教育陪伴等垂直需求切入。智元合伙人姚卯青预言,到2028年,具身智能在3C领域的渗透率将达到50%。
出海也是重要方向。东南亚市场需要便宜耐用的工厂机器人,中东市场需要耐高温的巡检机器人,非洲市场需要机器人做简易医疗支援。针对这些需求,企业需要推动产品本地化适配,开发差异化机型。
结语:从”能跑”到”能干活”还有多远
2026年的人形机器人产业,量产破万标志着从0到1的突破已经完成。但从”能跑”到”能干活”,从”工厂试用”到”家庭标配”,仍需跨越技术、成本与生态的鸿沟。
正如一位在工厂一线部署机器人的工程师所言:”现在机器人确实能完成很多动作,但工厂需要的不是动作,是稳定、可靠、低成本的解决方案。当机器人能在车间里像工人一样8小时连续稳定作业,不用频繁维修,不用专人看护,那才是真正’能用’了。”
这场由机器人驱动的产业变革,序幕已启。但高潮尚需时日。
相关阅读:
- 《量产破万台国产化率超85%,2026年人形机器人商业化成熟尚需时日》
- 《2026具身智能产业发展研究报告:量产拐点降临》