一、投资翻倍的表象与本质
2026年AI投资额预计翻倍至5810亿美元,这个数字足够震撼,但如果只盯着总量,很容易错过真正的趋势。
摩根大通预测,AI相关资本支出将从2025年的4500亿美元增长到2026年的7250亿美元。OpenAI完成1220亿美元私募融资,Anthropic完成300亿美元G轮融资,头部企业的估值门槛已提升至千亿美元级别。
但这轮投资热潮与五年前的AI泡沫有本质区别。
五年前,资本追逐的是“技术可能性”,任何一个能拿出demo的AI创业公司都能拿到融资,估值完全取决于团队背景和技术故事。如今,资本更看重“落地确定性”——谁能进入真实产业链,谁能让AI产生可量化的商业价值,谁才能获得资本认可。
“投AI已经从模型、团队和故事,转为看企业能否嵌进真实产业系统,能否借助一个区域的供应链、场景和数据完成落地。”一位头部 VC 合伙人在近期演讲中如是说。
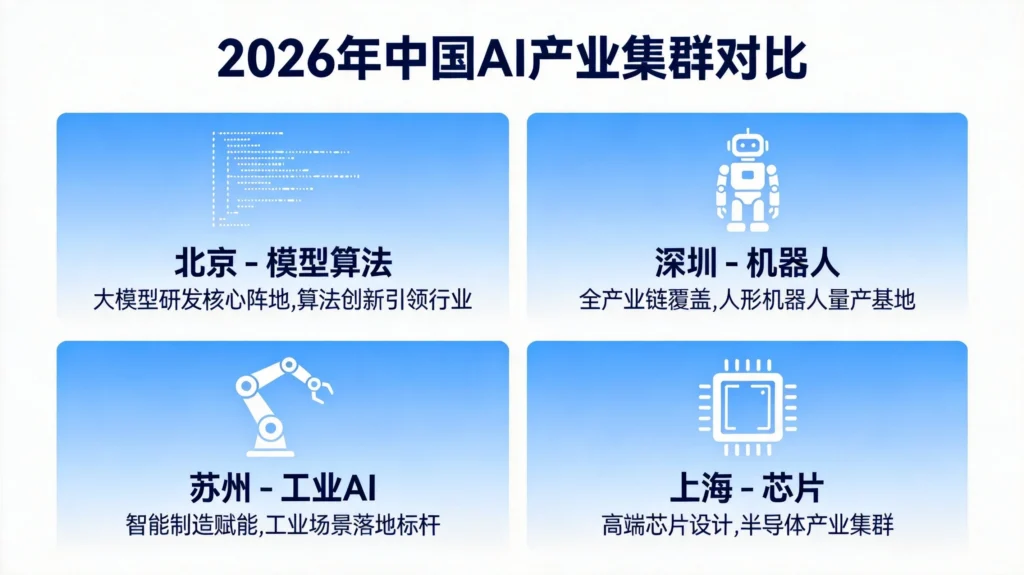
二、投资地理学:资本正在重新划定AI版图
IT桔子数据显示,2026年Q1共发生2865起融资事件,交易金额达2560亿元人民币。但资金分布正在高度集中:粤、苏、京、浙、沪五省市占据74.5%的融资事件和76.3%的融资金额。
如果只看表面,这像是资本继续押注一线城市的虹吸效应。但如果拆开来看,会发现资金并不是无差别涌向大城市,而是沿着不同产业带在做更精细的分配。
北京拿走的是模型、算法和高估值项目。上海吸走的是AI芯片企业——壁仞科技、燧原科技、天数智芯、瀚博半导体“GPU四小龙”悉数落子于此。深圳东莞圈走了机器人、具身智能、智能硬件——大疆、优必选、元戎启行、思谋科技背后是全球最完整的电子制造供应链。
苏州承接的是工业AI、汽车AI、企业级智能化。这里拥有1600多家“AI+制造”企业,数千家制造企业持续产生的设备、工艺和生产数据,让AI天然处在场景之中。
当这些城市放在一起看,会发现一个共性:AI企业并不是随机分布,而是沿着产业基础“长出来”的。这也解释了为什么“地域集中”会越来越明显——本质上是产业在筛选企业。
三、产业集群:AI商业化的最短物理路径
资本看重的,已经不只是公司本身,而是公司背后的“产业朋友圈”。
《中国独角兽企业发展报告2026》显示,以人工智能为代表的硬科技已占据独角兽企业中最亮眼的“C位”,69家企业、6380亿美元估值稳居全赛道第一。值得注意的是,超85%的AI独角兽们分布在京津冀、长三角、粤港澳大湾区三大城市群。
当融资和头部公司同时向同一批区域收缩,就很难再用“偶然”来解释。
一个底层的变化在于:AI正在从一个“纯软件行业”,变成一个越来越依赖现实世界的“半实体经济”。
在互联网时代,软件可以脱离具体场景独立生长,先做产品、再找用户。但在AI时代,仅仅把模型做出来已经不够,它必须进入真实业务流程,被反复调用、持续验证,并最终完成交付。
换句话说,AI的价值,不再体现在能不能做出来,而在于能不能在真实世界里跑起来,并且持续产生结果。
正因为如此,资本的判断标准发生了变化:从“投技术的可能性”转向“投落地的确定性”。而一旦进入落地这个阶段,产业集群的优势就体现出来了。
四、四类产业集群的AI估值逻辑
不同的产业集群,正在形成截然不同的AI估值逻辑。
北京:模型算法——“技术天花板”定价
北京是典型的“技术源头型集群”。《北京人工智能产业白皮书(2025)》显示,2025年上半年,北京全市人工智能核心产业规模已达2152.2亿元,截止2025年底,北京拥有超过2500家人工智能企业、备案大模型183款,均居全国首位。
这里聚集了智谱华章、月之暗面、光轮智能等公司。清华、北大等高校和顶尖科研资源长期积累的外溢,逐渐形成了“基础研究—模型训练—应用外溢”的完整链条。
在资本市场,北京AI企业的估值逻辑是“技术天花板”——谁能在国际权威评测榜单上拿到更好的名次,谁就能获得更高的估值。DeepSeek-V4与Kimi K2.6引领全球技术标杆,斯坦福AI指数报告显示中美模型差距缩至2.7%,这些技术突破正在重塑全球AI竞争格局。
深圳:机器人硬件——“量产能力”定价
深圳是机器人与智能硬件集群。完整的电子制造供应链,让这里成为具身智能硬件的天然孵化地。
《深圳智能眼镜产业高质量发展行动方案》提出,2027年产业链企业突破100家。宝安区聚集了60家产业链企业,形成“五公里产业圈”。欣旺达、兆威机电、立讯精密等企业,覆盖了从电池、传动到整机的完整链条。
在这个集群中,资本的估值逻辑是“量产能力”——谁能率先实现万台级交付,谁的毛利率更高,谁就能获得资本溢价。星动纪元2个月融资25亿,顺丰领投,正是因为它已经跑通了量产交付的商业闭环。
苏州:工业AI——“场景渗透率”定价
苏州提供了最典型的“制造场景”。这里拥有1600多家“AI+制造”企业,九识智能、镁伽科技、思必驰等公司直接嵌在产线旁边。
数千家制造企业持续产生的设备、工艺和生产数据,让AI不需要“找场景”,而是天然处在场景之中。机器视觉、预测性维护、工艺优化等应用,已经深入到苏州制造业的方方面面。
在这个集群中,资本的估值逻辑是“场景渗透率”——谁能在单一客户身上实现更高的AI渗透率,谁能从单一客户拓展到更多同类客户,谁就能获得资本青睐。
上海:AI芯片——“生态卡位”定价
上海是全国AI芯片企业最集中的区域,壁仞科技、燧原科技、天数智芯、瀚博半导体“GPU四小龙”都在这里。
AI芯片赛道的特殊性在于,它不仅是技术竞争,更是生态竞争。谁能进入主流服务器厂商的供应链,谁能适配主流大模型的训练框架,谁就能在这个赛道中占据有利位置。
资本的估值逻辑因此是“生态卡位”——谁在供应链中的位置更核心,谁的替代成本更高,谁就能获得估值溢价。
五、2026年AI投资的三条主线
沿着产业集群的逻辑,2026年的AI投资正在呈现三条清晰的主线。
主线一:算力基础设施
AI芯片、数据中心、算力服务构成了投资的最大板块。2026年5810亿美元的AI投资中,AI基础设施投资占比达54%,规模达3137亿美元。
芯片领域,投资规模达1278亿美元,同比增长65%,推理芯片成为投资新热点。数据中心领域,全球投资规模达1582亿美元,微软、谷歌、亚马逊、Meta四大科技巨头2026年资本支出合计达6300亿美元,其中超60%用于AI数据中心建设。
主线二:具身智能
人形机器人、工业机器人、服务机器人正在成为资本的新宠。星动纪元、Figure AI、智元机器人等企业接连获得大额融资,产业资本(顺丰、比亚迪等)开始直接介入,推动机器人从实验室走向真实场景。
主线三:垂直行业AI
制造业、医疗、交通等领域的AI应用逐步规模化。AI制药、AI辅诊、AI质检等细分赛道,正在诞生一批收入过亿、利润转正的企业。
这些赛道的共同特点是:技术成熟度已经过验证,商业模式的可行性已经过测试,资本需要做的是帮助企业扩大规模。
六、风险与机遇并存
尽管AI投资热度高涨,但行业仍面临三大风险。
风险一:投资结构性失衡
硬件环节投资占比过高,应用端投入产出失衡,部分应用项目商业化回报不及预期。90%的企业AI投资聚焦有明确商业回报的领域,但仍有10%的资金流向“概念炒作”。
风险二:高端算力缺口持续
7nm及以下制程高端GPU进口依赖度达75%,订单排期长达3-4周。在国际供应链不确定性加剧的背景下,国产替代的紧迫性日益凸显。
风险三:估值杠杆攀升
部分企业存在循环交易隐现等问题,潜在风险不容忽视。当资本市场情绪转冷,高估值企业的估值回调压力会显著增大。
但风险之外,机遇同样清晰。
国产AI芯片市占率从2024年的17%升至2026年的42%,追赶速度超预期。国产大模型在代码生成(SWE-Bench榜单)、多模态理解(OpenCompass评测)等领域已实现与国际顶尖模型的并肩。
更重要的是,中国AI企业正在从“技术跟随者”转型为“场景定义者”。在工业制造、物流配送、医疗诊断等场景中,中国AI企业积累的数据和经验,正在形成独特的竞争优势。
七、结语
2026年的AI投资翻倍,不是简单的资本热潮,而是一场估值逻辑的深刻变革。
资本正在沿着产业集群重新给AI公司定价,每一个产业集群都在形成独特的估值体系:北京看技术天花板,深圳看量产能力,苏州看场景渗透率,上海看生态卡位。
这场变革的本质,是AI从“虚拟经济”回归“实体经济”的必然选择。当技术不再是稀缺资源,当落地能力成为核心竞争力,产业集群的价值就会被重新发现。
对于AI创业者而言,这意味着创业的地理选择比以往任何时候都更重要——选择一个与自身业务匹配的产业集群,比单纯追求政策优惠更有价值。
对于投资者而言,这意味着需要更深入地理解产业、理解供应链、理解场景,而不仅仅是理解算法。
AI的下一程,属于那些能真正嵌入产业系统、为实体经济创造价值的公司。