
一、谷歌TPU v8:云端AI的自我进化
在Cloud Next ’26大会上,谷歌发布第八代TPU芯片,这是其在AI硬件领域的最新布局。
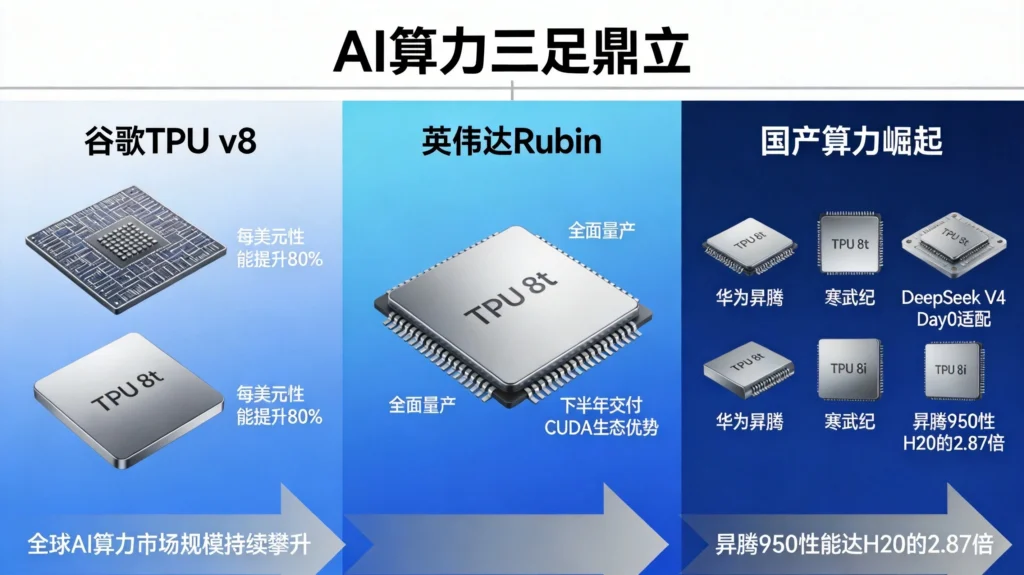
TPU v8分为两个版本:TPU 8t专攻训练,TPU 8i优化推理。这种分工策略本身就透露了谷歌的思考——训练和推理是两个不同的任务,需要不同的硬件优化。
TPU 8i的”每美元推理性能提升80%”这个数字值得关注。在AI应用大规模商用的背景下,推理成本正成为决定AI普惠程度的关键因素。当企业需要为数百万用户提供AI服务时,推理效率的每一点提升,都意味着成本的大幅下降。
谷歌的TPU战略从来不是单纯的芯片竞争,而是垂直整合的产物。通过TensorFlow、JAX等AI框架的深度优化,谷歌让TPU在自家生态中的表现远超竞品。数据显示,谷歌内部目前75%的新代码由AI生成,工程师的角色正从代码编写转向代码审核——这种效率提升的背后,是TPU算力的支撑。
更值得关注的是苹果的选择。谷歌云CEO库里安确认,基于Gemini技术构建的苹果新一代Siri将于2026年发布,双方签署了每年价值约10亿美元的多年期协议。这意味着,谷歌的AI能力将通过苹果的设备触达数十亿用户,TPU的算力将间接成为全球最广泛使用的AI算力之一。
二、英伟达Rubin:通用GPU的持续领先
面对谷歌的挑战,英伟达选择用 Rubin架构 回应。
Rubin架构芯片已进入全面生产阶段,预计将于2026年下半年交付。这将是继Hopper架构之后,英伟达推出的下一代AI超级计算机核心动力。
Rubin架构带来的提升是全方位的:更高的浮点运算能力、更大的内存带宽、更强的互联技术。这些参数听起来枯燥,却是支撑更大规模、更复杂AI模型训练的基础设施。
在AI训练领域,GPU的通用性依然是其最大优势。与TPU针对特定框架的优化不同,NVIDIA的GPU几乎可以运行任何AI模型,从PyTorch到TensorFlow,从Transformer到新型架构。这种灵活性让GPU成为大多数AI研究机构和企业的首选。
然而,通用性也意味着在特定场景下的效率可能不及专用芯片。谷歌的TPU在自家生态中的表现往往优于NVIDIA GPU,正是因为软硬一体的优化。
英伟达的应对策略是生态锁定。通过CUDA生态系统、cuDNN加速库、TensorRT推理优化工具等一系列软件基础设施,NVIDIA构建了极深的护城河。即使竞争对手的芯片性能相近,切换成本依然高昂。这解释了为什么即使面临TPU的竞争,大多数AI开发者依然选择NVIDIA。
三、国产算力的崛起:从”可用”到”好用”
在这场算力竞赛中,中国力量正在快速崛起。
2026年4月24日,DeepSeek V4发布,实现了全球首例模型发布即适配上线的Day0级速度——完成与华为昇腾、寒武纪、海光信息、摩尔线程、沐曦股份、昆仑芯、平头哥真武、天数智芯8大国产AI芯片的全链路优化。
华为昇腾950的表现尤为亮眼。V4-Pro在昇腾平台上单卡推理性能达到英伟达H20的2.87倍,8K输入场景下推理时延仅20ms,单卡每秒可处理4700个token。这意味着,在某些场景下,国产算力芯片已经可以与国际巨头正面竞争。
国金证券的研报指出,历经多轮技术打磨与应用反哺,国产算力芯片的性能与生态建设已跨过从”可用”向”好用”转变的关键拐点。凭借在本地化服务响应、成本控制以及适配国家战略导向上等方面的综合优势,国产算力设备正加速融入核心产业链。
国产算力崛起的深层逻辑是什么?
首先是政策驱动。国家将”开源开放”写入AI发展战略,地方政策提供实实在在的算力补贴。成都将2026年年度算力券支持总额提升至1亿元,单家主体最高补贴500万元;上海临港新片区为符合条件的AI创业团队提供最长3年免租和最高80%的算力费用补贴。这些政策为国产算力的应用创造了”低成本试验田”。
其次是架构创新。以MoE(混合专家)架构为代表的模型创新,大幅降低了推理时的算力需求。DeepSeek-V4-Flash的训练成本仅为传统方案的1%,这种效率革命让国产芯片有了与国际巨头同台竞技的可能。
第三是生态协同。DeepSeek V4与8大国产芯片的Day0级适配,标志着国产算力生态从”单点突破”走向”系统协同”。这种协同效应将进一步加速国产算力的成熟。
四、算力竞争的深层逻辑
表面上看,AI芯片竞争是技术之争;深层来看,这是一场生态之战。
芯片与框架的绑定
TPU与TensorFlow/JAX的深度整合,让谷歌在云端AI服务市场占据优势。当企业选择在谷歌云上部署AI应用时,TPU几乎是必然的选择。这种”芯片-框架-云服务”的一体化,是谷歌的核心竞争力。
NVIDIA的CUDA生态同样构建了深厚的壁垒。全球数百万AI开发者熟悉CUDA编程,数千个AI项目基于CUDA构建。这种生态惯性让NVIDIA即使面对专用芯片的竞争,依然保持领先。
国产芯片的生态建设同样在加速。华为昇腾的MindSpore框架、寒武纪的Bang语言,各有侧重、各具特色。但与国际巨头相比,国产算力生态的成熟度仍有提升空间。
成本与效率的博弈
AI芯片竞争的终极目标是让AI应用更便宜、更高效。
据全球最大的API聚合平台OpenRouter统计,2026年4月其平台周度累计Token消耗量相较去年同期提升约7-8倍,其中国产大模型贡献了主要增量。与此同时,受算力相关产能约束影响,全球算力价格出现上行趋势。
这种矛盾揭示了当前算力市场的现状:需求暴增,供给受限。英伟达Blackwell GPU涨价48%,H100月租破6.5万元,芯片交付频频推迟。在这样的背景下,任何能够提供高性价比算力的玩家,都有机会抢占市场份额。
国产芯片的性价比优势正在显现。以DeepSeek V4为例,其独创的混合注意力架构与KV Cache滑窗压缩技术,让V4-Pro处理长文本时算力消耗仅为上一代的27%,显存占用仅10%,推理成本降至国际竞品的1/70左右。
地缘政治的影响
AI芯片竞争从不是纯粹的商业博弈,地缘政治因素深刻影响着这场竞赛的走向。
美国对华芯片出口管制持续收紧,H100、H200等高端GPU获取受限,这反而倒逼了国产算力的快速成长。当”造不如买”的路径被堵死后,”自主可控”成为必然选择。
这种背景下,国产算力的崛起不仅是商业现象,更是国家战略的体现。从昇腾到寒武纪,从海光到摩尔线程,国产AI芯片正在构建完整的技术栈,为中国AI产业提供底层支撑。
五、投资机遇:算力产业链的全景图谱
AI芯片竞争的升温,为投资者勾勒出一条清晰的价值链。
上游:芯片设计与制造
芯片设计环节,华为昇腾、寒武纪、海光信息等已形成相对完整的国产替代方案。芯片制造环节,受限于先进制程,国产化率仍有提升空间。
中游:服务器与组网
拓维信息是华为昇腾生态的核心伙伴,唯一为DeepSeek提供兆瀚AI服务器的企业;紫光股份旗下新华三为DeepSeek提供AI服务器集群与UniCube训推一体机。服务器环节的毛利率相对稳定,是算力投资的重要组成。
下游:算力租赁与服务
中贝通信独家承接DeepSeek R1、V3、V4全系列模型的训练与推理任务,已投产可调度算力超10000P。算力租赁模式正在成为中小企业的首选,避免了自建数据中心的重资产投入。
配套:散热与供电
随着算力密度提升,散热成为制约算力扩展的关键因素。液冷技术成为主流方案,PUE(能效比)从传统的1.5+降低到1.3左右,绿色智算基地在中西部省份加速布局。
六、未来展望:算力竞争的下一步
展望未来,AI算力竞争将呈现三个趋势。
趋势一:专用化与通用化的融合
TPU代表专用化路线,GPU代表通用化路线,两者的边界正在模糊。NVIDIA在GPU中加入更多专用加速单元,谷歌在TPU中提升通用性。未来的AI芯片,可能是”通用基础+专用加速”的混合架构。
趋势二:国产替代的加速
在地缘政治和成本因素的双重驱动下,国产算力的渗透率将持续提升。预计到2027年,国内AI推理场景的国产芯片占比有望超过50%,训练场景的国产化也将取得突破。
趋势三:算力服务化
随着模型能力的增强和部署门槛的降低,”AI即服务”将进一步普及。中小企业无需采购昂贵的算力设备,通过API调用即可获得强大的AI能力。算力的边际成本将持续下降,推动AI应用的广泛普及。
结语
AI芯片的战争,远未到终局。
谷歌的TPU、英伟达的Rubin、国产的昇腾——三股力量在算力赛道上的角逐,本质上是AI产业话语权的争夺。谁掌握了算力,谁就掌握了AI时代的基础设施,也就在很大程度上决定了AI应用的发展方向。
对于中国AI产业而言,国产算力的崛起提供了另一种可能——在算力获取受限的情况下,依然可以支撑起庞大的AI应用生态。从DeepSeek V4的8芯片Day0适配,到昇腾950的2.87倍性能超越,国产力量正在用实际行动证明:算力自主可控,不是梦想,而是正在发生的事实。
2026年,AI算力战争进入新阶段。这场战争的胜负,不仅关乎技术,更关乎产业格局的重塑。
本文系AI行业门户原创内容,引用请注明来源。
发表回复